Ergo und der Autolykos-Konsensmechanismus: Teil II
20. Juni 2022

In der letzten Woche haben wir eine eingehende Untersuchung des Autolykos-Konsensmechanismus von Ergo vorgestellt. Mit diesem Artikel schließen wir den zweiten Teil dieser Diskussion ab und tauchen in weitere Details ein. Vor dem Lesen dieses Dokuments wird empfohlen, dass die Leser sich Teil I ansehen.
Zur Erinnerung, hier sind die Pseudocodes für das Block-Mining und die Hash-Funktion.
Autolykos Block Mining Pseudocode

Blake2b256 basierte Hash-Funktion

Linien 3, 4 – beginne die While-Schleife und das Raten
Nach der Berechnung von list R erstellt der Miner einen Nonce-Vorschlag und tritt in eine Schleife ein, um zu testen, ob der Nonce letztendlich eine Ausgabe erzeugt, die unter dem gegebenen Zielwert liegt.
Linien 5, 6 – Seed zur Generierung von Indizes
Linie 5, i = takeRight(8, H(m||nonce)) mod N, erzeugt eine Ganzzahl in [0,N). Algorithmus 3 wird verwendet, jedoch mit m und dem nonce als Eingaben. Sobald der Hash H(m||nonce) zurückgegeben wird, werden die 8 am wenigsten signifikanten Bytes beibehalten und dann durch mod N geleitet. Als Anmerkung sei erwähnt, dass der höchstmögliche ganzzahlige Wert mit 8 Bytes 264 – 1 ist, und unter der Annahme, dass N = 226, wird ein 8-Byte-Hash mod N dazu führen, dass die ersten paar Ziffern null sind. Die Anzahl der Nullen in i nimmt ab, während N wächst.
Linie 6 produziert e, einen Seed zur Indexgenerierung. Algorithmus 3 wird mit den Eingaben i (in Linie 5 generiert), h und M aufgerufen. Dann wird das am meisten signifikante Byte des numerischen Hashs verworfen, und die verbleibenden 31 Bytes werden als Wert e beibehalten. Es sollte auch erwähnt werden, dass der Wert e aus list R abgerufen werden kann, anstatt berechnet zu werden, da e ein r-Wert ist.
Linie 7 – Indexgenerator
Elementindex J wird unter Verwendung von Algorithmus 6 mit den Eingaben e, m, und nonce erstellt. Die Funktion genIndexes ist eine pseudorandomisierte Einwegfunktion, die eine Liste von k (=32) Zahlen in [0,N) zurückgibt.
genIndexes-Funktion

Es gibt ein paar zusätzliche Schritte, die im Pseudocode nicht gezeigt werden, wie z.B. ein Byteswap. Die Erstellung und Anwendung von genIndexes kann anhand des folgenden Beispiels erklärt werden:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash (d.h. Byteswap und Verketten von 4 Bytes durch Wiederholung der ersten 4 Bytes) = [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBEB58CA, 0x4E641798, 0x86BFE8C0]
Der folgende Python-Code zeigt den Prozess des Slicens des erweiterten Hashs, der k Indizes zurückgibt. In diesem Beispiel nehmen wir an, dass h < 614,400 ist, also N = 226 (67,108,864).
Slicing und mod N[1]
for i in range(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32(ItemCount)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32(ItemCount)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32(ItemCount)
Die Hauptaussage ist, dass das Slicen k Indizes zurückgibt, die pseudorandomisierte Werte sind, die aus dem Seed, d.h. e, m, und nonce abgeleitet sind.
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
Dieser Index kann in Werte in Basis 10 übersetzt werden, da er sich auf Zahlen in [0, N) bezieht. Zum Beispiel, 0x2BFE8C0 = 46131392, 0x3E8C0A1 = 65585313, 0xC0A1BA = 12624314, und so weiter. Der Miner verwendet diese Indizes, um k r Werte abzurufen.
Die genIndexes-Funktion verhindert Optimierungen, da es extrem schwierig, praktisch unmöglich ist, einen Seed zu finden, sodass genIndexes(seed) die gewünschten Indizes zurückgibt.
Linie 8 – Summe der r-Elemente gegeben k
Unter Verwendung des in Linie 7 generierten Index ruft der Miner die entsprechenden k (=32) r Werte aus list R ab und summiert diese Werte. Das mag verwirrend erscheinen, aber lassen Sie uns das aufschlüsseln.
Fortsetzung des obigen Beispiels, der Miner speichert die folgenden Indizes:
{0 | 46,131,392},
{1 | 65,585,313},
{2 | 12,624,314},
{3 | 10,599,011},
…
{31 | 8,830,952}
Angesichts der obigen Indizes ruft der Miner die folgenden r-Werte aus list R ab, die im Speicher gespeichert sind.
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12,624,314} → dropMsb(H(12,624,314||h||M))
{3 | 10,599,011} → dropMsb(H(10,599,011||h||M))
…
{31 | 8,830,952} → dropMsb(H(8,830,952||h||M))
Beachten Sie, dass Takeright(31), das auf einem 32-Byte-Hash arbeitet, auch als dropMsb – das am meisten signifikante Byte verwerfen – geschrieben werden kann.
Da der Miner bereits list R im RAM speichert, muss der Miner nicht k (= 32) Blake2b256-Funktionen berechnen und schaut stattdessen die Werte nach. Dies ist ein Schlüsselfeature der ASIC-Resistenz. Ein ASIC mit begrenztem Speicher muss 32 Blake2b256-Iterationen berechnen, um die Werte zu erhalten, die im Speicher nachgeschlagen werden könnten, und das Abrufen aus dem Speicher dauert viel weniger Zeit. Ganz zu schweigen davon, dass ein ASIC mit begrenztem Speicher 32 Blake2b256-Instanzen physisch auf dem Chip benötigen würde, um einen Hash pro Zyklus zu erreichen, was mehr Fläche und höhere Kosten erfordern würde. Es ist einfach zu beweisen, dass das Speichern von list R im Speicher den Aufwand wert ist. Nehmen wir Folgendes an: Eine GPU hat eine Hashrate von G = 100MH/s, _N = 226, k = 32, Blockintervall t = 120 Sekunden, und Elemente werden alle 4 Hashes nachgeschlagen. Ich gehe davon aus, dass Elemente alle 4 Hashes nachgeschlagen werden, da für jeden Nonce-Vorschlag mehrere Elemente wie i, J, und H(f) Instanzen von Algorithmus 3, d.h. blake2b-Hash, benötigen. Wir können schätzen, dass jeder r-Wert im Durchschnitt (G * k * t)/(N*4) = 1430,51 Mal verwendet wird.
Sobald die 32 r Werte nachgeschlagen werden, werden sie summiert.
Linien 9, 10, 11, 12 – Überprüfen, ob der Hash der Summe unter dem Ziel liegt
Die Summe der 32 r Werte wird mit Algorithmus 3 gehasht, und wenn die Ausgabe unter dem Ziel b liegt, ist der PoW erfolgreich, m und nonce werden an die Netzwerk-Knoten zurückgegeben, und der Miner wird in ERG belohnt. Wenn der Summen-Hash über dem Ziel liegt, werden Linien 4 – 11 mit einem neuen Nonce wiederholt.
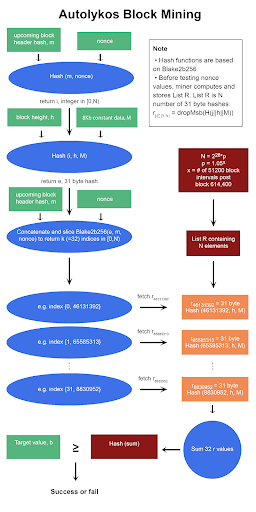
Wenn Sie es bis hierher geschafft haben, herzlichen Glückwunsch! Nach dem Lesen all dieser Informationen sollten Sie ein gutes Verständnis von Autolykos v2 haben! Wenn Sie eine visuelle Demonstration von Autolykos sehen möchten, werfen Sie bitte einen Blick auf die Grafik am Ende dieses Dokuments. Wenn Sie eine Videoerklärung wünschen, finden Sie diese hier.
ASIC-Resistenz
Wir wissen von Ethereum, dass „speicherintensive“ Algorithmen durch die Integration von Speicher auf ASICs überwunden werden können. Ergo ist anders, aber lassen Sie uns zuerst überprüfen, warum ein ASIC mit begrenztem Speicher uncompetitive ist und warum ein Miner list R speichern muss. Linie 8 des Autolykos-Block-Mining schreckt Maschinen mit begrenztem Speicher ab. Wenn ein ASIC-Miner list R nicht speichert, benötigt er viele Kerne, um die 31-Byte-numerischen Hashes im Fluss zu generieren. 32 r Werte können nicht effizient mit einer einzigen Kernschleife berechnet werden, da eine Ausgabe nur alle 32 Hash-Zyklen erzeugt werden würde. Angesichts von J, um einen Nonce pro Hash-Zyklus zu berechnen, sind mindestens 32 Blake2b256-Instanzen erforderlich, die dropMsb(H(j||h||M)) ausführen. Wie oben erwähnt, erhöht dies die Chipgröße und die Kosten erheblich. Es ist klar, dass das Speichern von list R lohnenswert ist, da es sehr teuer ist, 32 oder sogar 16 Kerne zu haben. Um es auf den Punkt zu bringen: Das Lesen von Speicher ist schneller als das Berechnen von Blake-Instanzen jedes Mal, wenn ein Nonce getestet wird.
Lassen Sie uns sehen, ob ein ASIC mit ausreichend Speicher wettbewerbsfähig ist, da dies für die Diskussion relevanter ist. Im Vergleich zwischen Ethash und Autolykos besteht der Unterschied darin, dass Ethash N Elemente beim Hashen des Nonce und Header 64 Mal mischt, während Autolykos N Elemente beim Abrufen von 32 r Werten basierend auf generierten Indizes verwendet. Für jeden getesteten Nonce führt Autolykos etwa 4 Blake2b256-Instanzen und 32 Speicherabrufe aus, während Ethash etwa 65 SHA-3-ähnliche Instanzen und 64 Speicherabrufe ausführt. Ganz zu schweigen davon, dass k derzeit auf 32 eingestellt ist, dieser Wert jedoch erhöht werden kann, um mehr r Werte abzurufen, wenn nötig. ASICs, die Ethash ausführen, haben viel Spielraum, um die SHA3-Hashgeschwindigkeit zu erhöhen, da 65 Hashes pro getesteten Nonce abgeschlossen werden, verglichen mit etwa 4 bei Autolykos. Das Verhältnis von Speicherabrufen zu Hash-Instanzen ist bei Autolykos viel größer. Aus diesem Grund ist Autolykos speicherintensiver als Ethash, da die Speicherbandbreite eine viel größere Rolle spielt als die Hashgeschwindigkeit.
Ein Bereich, in dem Optimierungen bei Autolykos stattfinden könnten, ist das Füllen von list R. Das Füllen von list R erfordert N Instanzen einer Blake2b256-Funktion. N ist groß und wird nur größer, also ist das eine Menge Hashing. Ein ASIC könnte die Geschwindigkeit von Blake2b256 optimieren, was mehr Zeit für das Block-Mining bieten würde, da list R schneller gefüllt wird. Obwohl dies möglich ist, erfordert das Füllen von list R das Durchlaufen von [0, N) und eine GPU mit 32 breiten Multiprozessoren kann list R bereits sehr schnell (in Sekunden) füllen. Man bräuchte einen ASIC mit vielen Blake-Kernen, um signifikant schneller zu sein – wieder sehr teuer und wahrscheinlich nicht lohnenswert, da der Engpass die Speicher-_Schreib-_Bandbreite (d.h. das Schreiben von list R in den RAM anstelle der Hashgeschwindigkeit) werden könnte.
Der letzte Bereich, der für Autolykos optimiert werden kann, ist die Lese-/Schreibgeschwindigkeit des Speichers. Ethash-ASIC-Miner haben eine etwas schnellere Lesegeschwindigkeit im Vergleich zu GPUs, da der Speicher höher getaktet ist, ohne die Auswirkungen der GPU-Drosselung. Dieser Unterschied ist jedoch ziemlich unbedeutend und wird voraussichtlich noch unbedeutender werden, da GPUs fortschreiten. Dies liegt daran, dass die Speicherhardware selbst gleich ist: DRAM. Man könnte sich fragen, ob eine schnellere Speicherhardware genutzt werden könnte, bei der die Lese- und Schreibgeschwindigkeit des Speichers viel schneller ist… SRAM könnte beispielsweise ein vorstellbarer nächster Schritt sein, um speicherintensive Algorithmen zu brechen, jedoch ist SRAM keine praktikable Lösung, einfach weil es weniger dicht ist.
SRAM auf FPGA[2]

Das obige Foto zeigt ein FPGA mit 8 Speichermodulen auf der Vorderseite, und es gibt weitere 8 auf der Rückseite. Der gesamte SRAM-Speicher beträgt nur 576MB. Ausreichend SRAM auf einem Chip unterzubringen, wird nicht funktionieren, da der SRAM weiter vom Kern entfernt platziert werden muss, da er nicht dicht genug ist, um in einer Schicht um den Kern herum zu passen. Dies kann zu Lese-/Schreibverzögerungen führen, da der Strom längere Strecken zurücklegen muss, obwohl die Hardware selbst schneller ist. Darüber hinaus steigen die Speicheranforderungen zum Mining von Ergo, wenn N steigt, sodass es nicht machbar ist, ausreichend SRAM im Laufe der Zeit unterzubringen. Daher sind SRAM-ASICs nicht wert, erforscht zu werden, selbst wenn man genug Geld für SRAM selbst ausgeben könnte.
Blake2b256
Ein wesentlicher Unterschied zwischen einem Algorithmus wie Autolykos und anderen ist die Verwendung von Blake2b256. Das ist kein Zufall. Blake verlässt sich stark auf Additionsoperationen für das Hash-Mischen anstelle von XOR-Operationen. Eine Operation wie XOR kann bitweise durchgeführt werden, während Addition Übertragsbits erfordert. Daher benötigt Blake mehr Leistung und Kernfläche im Vergleich zu SHA-Algorithmen, ist aber dennoch ebenso sicher und tatsächlich schneller. Wie auf der Blake2-Website erwähnt, „ist BLAKE2 in Software schnell, weil es Merkmale moderner CPUs ausnutzt, nämlich Parallelität auf Befehlsebene, SIMD-Befehlssatzerweiterungen und mehrere Kerne.“[3] Daher kann ein ASIC zwar Blake-Instanzen schneller ausgeben, aber die innere Natur der Funktion begrenzt Optimierungen, da Addition erforderlich ist und Merkmale beinhaltet, die sowohl in CPUs als auch in GPUs zu finden sind.
Blake2b-Geschwindigkeit im Vergleich zu anderen Hash-Funktionen
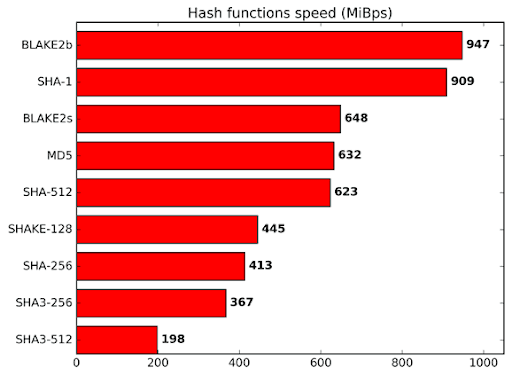
Fazit
Autolykos ist eine großartige Innovation, die eine notwendige Antwort auf den Anstieg von PoW-optimierten ASIC-Maschinen darstellt. Wir hoffen, dass diese 2-teilige Serie Ihnen geholfen hat, Autolykos auf einer technischeren Ebene zu verstehen und warum es speicherintensiver ist als Ethash. Während Ethereum zu einem PoS-Netzwerk übergeht, wird es eine große Gemeinschaft von Minern geben, die nach einem Ort suchen, um ihre Hashrate-Power zu lenken, und Ergo sollte ein bedeutender Akteur sein, um diese Miner anzuziehen.
Wenn Ihnen dieser Artikel gefallen hat, lädt der Autor Sie ein, weitere Inhalte über seinen Twitter-Account zu überprüfen, @TheMiningApple.
[1] Kredit an Wolf9466#9466 auf Discord
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post

{kind=link}
13. August 2025
12. August 2025
9. Juli 2025
12. Mai 2025
9. Dezember 2024
19. August 2024