Ergo e il meccanismo di consenso di Autolykos: parte II
28 agosto 2022

La scorsa settimana abbiamo introdotto un'analisi approfondita del meccanismo di consenso Autolykos di Ergo. Con questo articolo, completiamo la seconda parte di quella discussione e ci addentriamo in ulteriori dettagli. Prima di leggere questo documento, si raccomanda ai lettori di dare un'occhiata alla Parte I.
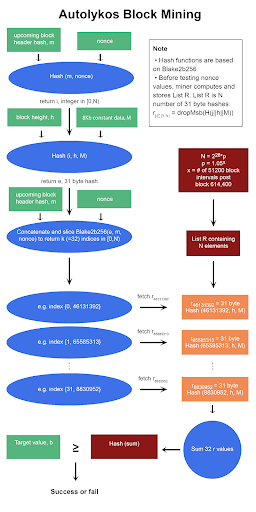
Come promemoria, ecco gli pseudocodici delle funzioni di block mining e hash.
Autolykos Block Mining Pseudocode

Funzione hash basata su Blake2b256

Righe 3, 4 – inizia mentre loop e indovina
Dopo aver calcolato list R, il miner crea un'ipotesi nonce ed entra in un ciclo per verificare se il nonce alla fine crea un output che è inferiore al valore target specificato.
Righe 5, 6 – seme per la generazione di indici
Riga 5, i = takeRight(8, H(m||nonce)) mod N, produce un intero in [0,N). L'algoritmo 3 viene utilizzato ma con m e nonce come input. Una volta restituito l'hash H(m||nonce), gli 8 byte meno significativi vengono conservati e quindi passati attraverso mod N. Come nota a margine, il valore intero più alto possibile con 8 byte è 264 – 1, e supponendo N = 226, risulterà un hash a 8 byte mod N nelle prime cifre essendo zero. Il numero di zeri in i diminuisce all'aumentare di N.
La riga 6 produce e, un seme per la generazione dell'indice. L'algoritmo 3 viene chiamato con gli ingressi i (generati nella riga 5), _h_ e M. Quindi, il byte più significativo dell'hash numerico viene eliminato e i restanti 31 byte vengono mantenuti come valore e. Va inoltre notato che il valore e può essere recuperato da list R invece di essere calcolato poiché e è un valore r.
Riga 7 – generatore di indici
L'indice dell'elemento J viene creato utilizzando l'algoritmo 6 con gli ingressi e, m, e nonce. La funzione genIndexes è un modo pseudocasuale che restituisce un elenco di k (=32) numeri in [0,N).
funzione genIndexes

Ci sono un paio di passaggi aggiuntivi che non sono mostrati nello pseudocodice come un byteswap. La creazione e l'applicazione di genIndexes può essere spiegata tramite il seguente esempio:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash (ovvero scambiare byte e concatenare 4 byte ripetendo i primi 4 byte) = [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBCEB58CA, 0x4E641798, 0x86]
Il seguente codice Python mostra il processo di slicing dell'hash esteso, restituendo k indici. In questo esempio assumiamo h < 614.400, quindi N = 226 (67.108.864).
Tagliare e modificare N[1]
per i nell'intervallo(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32( Conteggio articoli)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32( Conteggio articoli)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32( Conteggio articoli)
L'assunto principale è che lo slicing restituisce k indici che sono valori pseudocasuali derivati dal seme, ovvero e, m, e nonce.
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
Questo indice può essere tradotto in valori in base 10 in quanto si riferisce a numeri in [0, N). Ad esempio, 0x2BFE8C0 = 46131392, 0x3E8C0A1 = 65585313, 0xC0A1BA = 12624314 e così via. Il miner utilizza questi indici per recuperare i valori k r.
La funzione genIndexes impedisce le ottimizzazioni poiché è estremamente difficile, praticamente impossibile, trovare un seme tale che genIndexes(seed) restituisca gli indici desiderati.
Riga 8 – somma di r elementi dati k
Utilizzando l'indice generato nella riga 7, il miner recupera i valori k (=32) r corrispondenti da list R e somma questi valori. Potrebbe sembrare confuso, ma analizziamolo.
Continuando l'esempio sopra, il miner memorizza i seguenti indici:
{0 | 46.131.392},
{1 | 65.585.313},
{2 | 12.624.314},
{3 | 10.599.011},
…
{31 | 8.830.952}
Dati gli indici sopra, il miner recupera i seguenti valori r da list R archiviato in memoria.
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12.624.314} → dropMsb(H(12.624.314||h||M))
{3 | 10.599.011} → dropMsb(H(10.599.011||h||M))
…
{31 | 8.830.952} → dropMsb(H(8.830.952||h||M))
Nota che Takeright(31) operato su un hash a 32 byte può anche essere scritto come dropMsb – elimina il byte più significativo.
Poiché il miner memorizza già list R nella RAM, il miner non ha bisogno di calcolare k (= 32) funzioni Blake2b256 e cerca invece i valori. Questa è una caratteristica fondamentale della resistenza ASIC. Un ASIC con memoria limitata deve calcolare 32 iterazioni Blake2b256 per ottenere i valori che avrebbero potuto essere cercati in memoria e il recupero dalla memoria richiede molto meno tempo. Per non parlare del fatto che un ASIC con memoria limitata richiederebbe fisicamente 32 istanze Blake2b256 per ottenere un hash per ciclo, il che richiederebbe più area e costi più elevati. È semplice dimostrare che l'archiviazione di list R in memoria vale il compromesso. Si supponga quanto segue, una GPU ha un hash rate di G = 100MH/s, _N = 226, k = 32, intervallo di blocco t = 120 secondi e gli elementi vengono cercati ogni 4 hash. Mi piace presumere che gli elementi vengano cercati ogni 4 hash perché, per ogni ipotesi nonce, più elementi come i, J, e H(f) richiedono l'algoritmo 3, ovvero blake2b hash, istanze. Possiamo stimare che ogni valore r verrà utilizzato, in media, (G * k * t)/(N*4) = 1430,51 volte.
Una volta che i 32 valori r sono stati cercati, vengono sommati.
Riga 9, 10, 11, 12 – controlla se l'hash della somma è inferiore al target
La somma dei 32 valori r viene sottoposta a hash utilizzando l'algoritmo 3 e, se l'output è al di sotto del target b, il PoW ha esito positivo, m e nonce vengono restituiti ai nodi di rete e il minatore viene ricompensato in ERG. Se l'hash della somma è al di sopra del target, le Linee 4 – 11 vengono ripetute con un nuovo nonce.
Se sei arrivato fin qui, congratulazioni! Dopo aver letto tutte queste informazioni, dovresti avere una buona conoscenza di Autolykos v2! Se desideri vedere una dimostrazione visiva di Autolykos, guarda il grafico alla fine di questo documento. Se desideri una spiegazione video, puoi trovarla qui.
Resistenza ASIC
Sappiamo da Ethereum che gli algoritmi di "memoria dura" possono essere conquistati integrando la memoria sugli ASIC. Ergo è diverso, ma prima rivediamo perché un ASIC con memoria limitata non è competitivo e perché un minatore deve memorizzare list R. La riga 8 del block mining di Autolykos scoraggia le macchine con memoria limitata. Se un minatore ASIC non memorizza list R, richiede molti core per generare gli hash numerici a 31 byte al volo. 32 valori r non possono essere calcolati in modo efficiente utilizzando un loop core singolo perché un output verrebbe generato solo ogni 32 ciclo hash. Dato J, per calcolare un nonce per ciclo hash, sono necessarie almeno 32 istanze Blake2b256 che eseguono dropMsb(H(j||h||M)). Come accennato in precedenza, ciò aumenta notevolmente le dimensioni e il costo dello stampo. È chiaro che vale la pena archiviare list R perché avere 32 o anche 16 core è molto costoso. Più precisamente, leggere la memoria è più veloce che calcolare le istanze di Blake ogni volta che viene testato un nonce.
Vediamo se un ASIC con memoria sufficiente è competitivo perché è più rilevante per la discussione. Confrontando Ethash e Autolykos, la differenza è che Ethash coinvolge N elementi durante l'hashing del nonce e l'intestazione si mescola 64 volte, mentre Autolykos coinvolge N elementi quando recupera 32 valori r in base agli indici generati. Per ogni nonce testato, Autolykos esegue circa 4 istanze Blake2b256 e 32 recuperi di memoria mentre Ethash esegue circa 65 istanze simili a SHA-3 e 64 recuperi di memoria. Per non parlare del fatto che k è attualmente impostato su 32 ma questo valore può essere aumentato per recuperare più valori r se necessario. Gli ASIC che eseguono Ethash hanno molto spazio per aumentare la velocità di hash SHA3 poiché 65 hash vengono completati per nonce testato rispetto a circa 4 su Autolykos. Il rapporto tra recuperi di memoria e istanze hash è molto maggiore su Autolykos. Per questo motivo, Autolykos ha una memoria più rigida di Ethash poiché la larghezza di banda della memoria gioca un ruolo molto più importante rispetto alla velocità di hashing.
Un'area in cui potrebbe aver luogo l'ottimizzazione di Autolykos è il riempimento di list R. Il riempimento di list R richiede N istanze di una funzione Blake2b256. N è grande e sta diventando sempre più grande, quindi è un sacco di hashing. Un ASIC potrebbe ottimizzare la velocità di Blake2b256, ottenendo più tempo per il block mining poiché list R viene riempita prima. Anche se questo può essere fatto, riempire l'elenco R richiede il ciclo di [0, N) e una GPU con multiprocessori a 32 larghezze può già riempire l'elenco R molto velocemente (in secondi). Avrebbe bisogno di un ASIC con molti core Blake per essere significativamente più veloce, ancora una volta, molto costoso e probabilmente non utile poiché il collo di bottiglia potrebbe diventare memoria write larghezza di banda (cioè, scrivere list R su RAM piuttosto che velocità di hashing).
L'ultima area che può essere ottimizzata per Autolykos è la velocità di lettura/scrittura della memoria. I minatori Ethash ASIC hanno una velocità di lettura leggermente superiore rispetto alle GPU poiché la memoria ha un clock superiore senza l'effetto della limitazione della GPU. Tuttavia, questa differenza è piuttosto insignificante e dovrebbe diventare più insignificante con l'avanzare delle GPU. Questo perché l'hardware di memoria è lo stesso: DRAM. Ci si potrebbe chiedere se potrebbe essere utilizzato un hardware di memoria più veloce per cui la velocità di lettura e scrittura della memoria è molto più veloce ... SRAM, ad esempio, potrebbe essere un passo successivo immaginabile nella rottura degli algoritmi rigidi della memoria, tuttavia, SRAM non è una soluzione fattibile semplicemente perché è meno denso.
SRAM su FPGA[2]

La foto sopra è un FPGA con 8 chip di memoria sulla parte anteriore e ce ne sono altri 8 sul retro. La memoria SRAM totale è di soli 576 MB. Il montaggio di una SRAM sufficiente su un dado non funzionerà perché la SRAM dovrà essere posizionata più lontano dal nucleo poiché è sufficientemente densa da poter essere inserita in uno strato attorno al nucleo. Ciò può comportare ritardi di lettura/scrittura perché l'elettricità deve percorrere distanze maggiori anche se l'hardware stesso è più veloce. Inoltre, per estrarre Ergo, il requisito di memoria aumenta all'aumentare di N, quindi non è possibile montare una SRAM sufficiente nel tempo. Pertanto, gli ASIC SRAM non valgono la pena esplorare anche se si disponeva di denaro sufficiente da spendere per la stessa SRAM.
Blake2b256
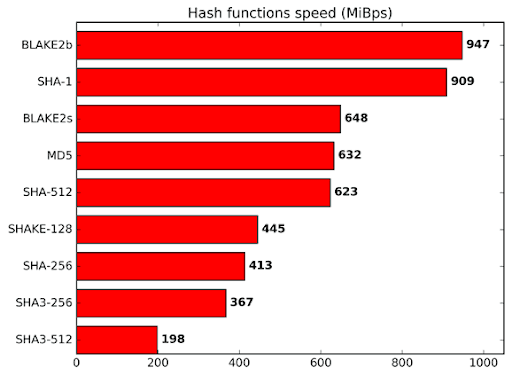
Una delle principali differenze tra un algoritmo come Autolykos e altri è l'uso di Blake2b256. Questa non è una coincidenza. Blake fa molto affidamento sulle operazioni di addizione per il missaggio hash invece delle operazioni XOR. Un'operazione come XOR può essere eseguita bit per bit mentre l'aggiunta richiede bit di riporto. Pertanto, Blake richiede più potenza e area centrale rispetto agli algoritmi SHA, ma è comunque altrettanto sicuro e, di fatto, più veloce. Come menzionato sul sito Web di Blake2, "BLAKE2 è veloce nel software perché sfrutta le funzionalità delle moderne CPU, vale a dire il parallelismo a livello di istruzione, le estensioni del set di istruzioni SIMD e più core".[3] Pertanto, mentre un ASIC può produrre istanze Blake più velocemente , la natura innata della funzione limita le ottimizzazioni richiedendo l'aggiunta e coinvolgendo funzionalità presenti nelle CPU e nelle GPU.
Velocità di Blake2b rispetto ad altre funzioni hash
Conclusione
Autolykos è una grande innovazione, una risposta necessaria per combattere l'ascesa di macchine ASIC ottimizzate per PoW. Ci auguriamo che questa serie in 2 parti ti abbia aiutato a capire Autolykos a un livello più tecnico e perché ha più memoria difficile di Ethash. Man mano che Ethereum passerà a una rete PoS, ci sarà una vasta comunità di minatori in cerca di un posto dove dirigere il loro potere di hashrate, ed Ergo dovrebbe essere un attore significativo nell'attirare quei minatori.
Se ti è piaciuto questo articolo, l'autore ti invita a controllare più contenuti tramite il suo account Twitter, @TheMiningApple.
[1] Ringraziamo Wolf9466#9466 su Discord
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post

13 agosto 2025




9 luglio 2025

12 maggio 2025













7 agosto 2022


{kind=link}