Ergo与Autolykos共识机制:第二部分
2022年6月20日

上周,我们介绍了对Ergo的Autolykos共识机制的深入探讨。通过这篇文章,我们完成了该讨论的第二部分,并深入探讨了更多细节。在阅读本文之前,建议读者先查看第一部分。
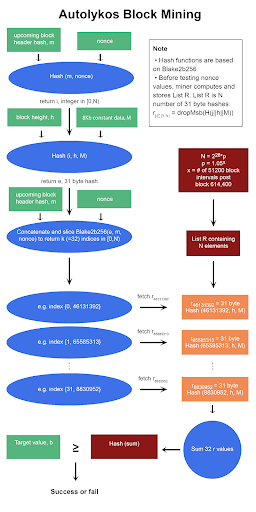
作为提醒,这里是区块挖掘和哈希函数的伪代码。
Autolykos区块挖掘伪代码

基于Blake2b256的哈希函数

第3、4行 – 开始while循环和猜测
在计算完_list R_后,矿工创建一个随机数猜测并进入循环,以测试该随机数是否最终生成低于给定目标值的输出。
第5、6行 – 生成索引的种子
第5行,i = takeRight(8, H(m||nonce)) mod N,生成一个在[0,N)范围内的整数。使用算法3,但输入为_m_和_nonce_。一旦哈希_H(m||nonce)_返回,保留8个最低有效字节,然后通过_mod N_传递。顺便提一下,8字节的最高可能整数值为264 – 1,假设_N = 226,8字节哈希_mod N_将导致前几个数字为零。随着_N_的增长,_i_中的零的数量减少。
第6行生成_e_,用于索引生成的种子。算法3使用输入_i_(在第5行生成)、h_和_M。然后,丢弃数字哈希的最高有效字节,保留剩余的31个字节作为值_e_。还应注意,值_e_可以从_list R_中检索,而不是计算,因为_e_是一个_r_值。
第7行 – 索引生成器
元素索引_J_使用算法6创建,输入为_e、m_和_nonce_。函数genIndexes是一个伪随机单向函数,返回一个在[0,N)范围内的_k_(=32)个数字的列表。
genIndexes函数

有几个额外的步骤未在伪代码中显示,例如字节交换。genIndexes的创建和应用可以通过以下示例进行解释:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash(即字节交换并通过重复前4个字节连接4个字节)= [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBEB58CA, 0x4E641798, 0x86BFE8C0]
以下python代码展示了切片扩展哈希的过程,返回k个索引。在这个例子中,我们假设_h_ < 614,400,因此N = 226(67,108,864)。
切片和mod N[1]
for i in range(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32(ItemCount)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32(ItemCount)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32(ItemCount)
主要的收获是切片返回_k_个索引,这些索引是从种子即_e、m_和_nonce_派生的伪随机值。
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
这个索引可以转换为十进制值,因为它指的是[0, N)范围内的数字。例如,0x2BFE8C0 = 46131392,0x3E8C0A1 = 65585313,0xC0A1BA = 12624314,等等。矿工使用这些索引来检索_k r_值。
genIndexes函数防止了优化,因为找到一个种子使得genIndexes(seed)返回所需索引是极其困难的,基本上是不可能的。
第8行 – 给定k的r元素之和
使用在_第7行_生成的索引,矿工从_list R_中检索相应的_k(=32)r_值并对这些值求和。这可能听起来令人困惑,但让我们分解一下。
继续上面的例子,矿工存储以下索引:
{0 | 46,131,392},
{1 | 65,585,313},
{2 | 12,624,314},
{3 | 10,599,011},
…
{31 | 8,830,952}
根据上述索引,矿工从存储在内存中的_list R_中检索以下r值。
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12,624,314} → dropMsb(H(12,624,314||h||M))
{3 | 10,599,011} → dropMsb(H(10,599,011||h||M))
…
{31 | 8,830,952} → dropMsb(H(8,830,952||h||M))
注意,_Takeright(31)在32字节哈希上操作也可以写为_dropMsb – 丢弃最高有效字节。
由于矿工已经在RAM中存储了_list R_,矿工不需要计算_k(= 32)个Blake2b256函数,而是查找这些值。这是ASIC抗性的一项关键特性。具有有限内存的ASIC需要计算32个Blake2b256迭代以获取可以在内存中查找的值,而从内存中获取所需的时间要少得多。更不用说,具有有限内存的ASIC需要在芯片上物理上拥有32个Blake2b256实例,以实现每个周期一个哈希,这将需要更多的面积和更高的成本。很简单地证明,将_list R_存储在内存中是非常值得的。假设以下情况,GPU的哈希率为_G = 100MH/s,N = 226,k = 32,区块间隔_t = 120秒,并且每4个哈希查找一次元素。我喜欢假设每4个哈希查找一次元素,因为对于每个随机数猜测,多个元素如_i、J_和_H(f)需要算法3,即blake2b哈希实例。我们可以估计每个r值平均将被使用(G * k * t)/(N*4)_ = 1430.51次。
一旦查找了32个_r_值,它们就会被求和。
第9、10、11、12行 – 检查和的哈希是否低于目标
32个_r_值的和使用算法3进行哈希,如果输出低于目标_b_,则PoW成功,m_和_nonce_被返回给网络节点,矿工获得ERG奖励。如果和的哈希高于目标,则重复_第4 – 11行,使用新的随机数。
如果你能看到这里,恭喜你!在阅读了所有这些信息后,你应该对Autolykos v2有了很好的理解!如果你想看到Autolykos的可视化演示,请查看本文档末尾的图形。如果你想要视频解释,可以在这里找到。
ASIC抗性
我们从以太坊知道,“内存硬”算法可以通过在ASIC上集成内存来征服。Ergo是不同的,但让我们首先回顾一下为什么具有有限内存的ASIC不具竞争力,以及矿工为什么需要存储_list R_。Autolykos区块挖掘的第8行阻止了具有有限内存的机器。如果ASIC矿工不存储_list R_,他们需要大量核心来实时生成31字节的数字哈希。32个_r_值不能通过单核心循环有效计算,因为每32个哈希周期只会生成一个输出。给定_J_,要计算一个随机数_每个哈希周期_,至少需要32个Blake2b256实例运行_dropMsb(H(j||h||M))_。正如我们上面提到的,这显著增加了芯片的尺寸和成本。显然,存储_list R_是值得的,因为拥有32个,甚至16个核心是非常昂贵的。更重要的是,读取内存的速度比每次测试随机数时计算Blake实例的速度要快。
让我们看看具有足够内存的ASIC是否具有竞争力,因为这与讨论更相关。比较Ethash和Autolykos,区别在于Ethash在哈希随机数和头部时涉及N个元素,并且混合64次,而Autolykos在根据生成的索引获取32个_r_值时涉及N个元素。对于每个测试的随机数,Autolykos大约运行4个Blake2b256实例和32次内存获取,而Ethash大约运行65个SHA-3类实例和64次内存获取。更不用说,_k_目前设置为32,但如果需要,可以增加该值以检索更多_r_值。运行Ethash的ASIC有很大的空间来提高SHA3哈希速度,因为每个测试的随机数完成65个哈希,而Autolykos大约完成4个。内存获取与哈希实例的比率在Autolykos上要大得多。因此,Autolykos比Ethash更具内存硬性,因为内存带宽在哈希速度中扮演了更大的角色。
Autolykos优化的一个领域是填充_list R_。填充_list R_需要_N_个Blake2b256函数实例。N_很大并且只会变得更大,因此这需要大量的哈希。ASIC可以优化Blake2b256的速度,从而为区块挖掘赢得更多时间,因为_list R_会更快填充。尽管可以这样做,但填充_list R_需要遍历[0, N),而具有32宽多处理器的GPU已经可以非常快速地填充_list R(在几秒钟内)。要显著更快,需要一个具有许多Blake核心的ASIC – 再次,非常昂贵,并且可能不值得,因为瓶颈可能变成内存_写入_带宽(即,将_list R_写入RAM而不是哈希速度)。
可以优化Autolykos的最后一个领域是内存读/写速度。与GPU相比,Ethash ASIC矿工的读取速度稍快,因为内存时钟更高而不受GPU节流的影响。然而,这种差异相当微不足道,并且预计随着GPU的进步而变得更加微不足道。这是因为内存硬件本身是相同的:DRAM。人们可能会质疑是否可以利用更快的内存硬件,从而使内存读写速度更快……例如,SRAM可能是打破内存硬算法的下一个想象步骤,然而,SRAM并不是一个可行的解决方案,因为它的密度较低。
FPGA上的SRAM[2]

上面的照片是一个前面有8个内存芯片的FPGA,背面还有8个。总SRAM内存只有576MB。在芯片上放置足够的SRAM是行不通的,因为SRAM需要放置得离核心更远,因为它的密度不足以在核心周围放置一层。这可能导致读/写延迟,因为电流需要走更长的距离,尽管硬件本身更快。此外,为了挖掘Ergo,内存需求随着N的增加而增加,因此随着时间的推移,放置足够的SRAM是不可行的。因此,即使有人有足够的现金来购买SRAM,SRAM ASIC也不值得探索。
Blake2b256
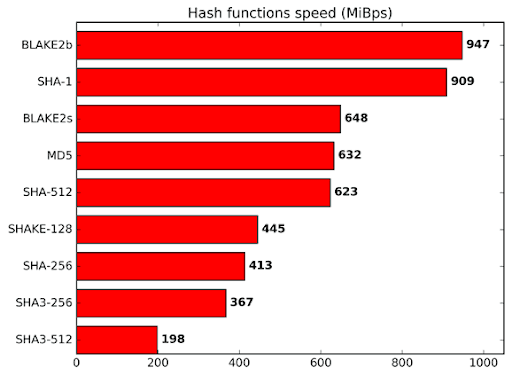
像Autolykos这样的算法与其他算法之间的一个主要区别是使用Blake2b256。这并非偶然。Blake在哈希混合中严重依赖加法运算,而不是XOR运算。像XOR这样的操作可以逐位进行,而加法则需要进位位。因此,Blake相比SHA算法需要更多的功率和核心面积,但它仍然是安全的,实际上更快。正如Blake2网站上提到的,“BLAKE2在软件中运行快速,因为它利用了现代CPU的特性,即指令级并行性、SIMD指令集扩展和多个核心。”[3]因此,虽然ASIC可以更快地输出Blake实例,但该函数的固有特性通过要求加法和涉及CPU以及GPU中发现的特性来限制优化。
Blake2b相对于其他哈希函数的速度
结论
Autolykos是一项伟大的创新,是对抗PoW优化ASIC机器崛起的必要回应。我们希望这两部分系列文章能帮助你更深入地理解Autolykos及其为何比Ethash更具内存硬性。随着以太坊过渡到PoS网络,将会有大量矿工寻找一个地方来指引他们的哈希率,而Ergo应该在吸引这些矿工方面发挥重要作用。
如果你喜欢这篇文章,作者邀请你通过他们的Twitter账号**@TheMiningApple**查看更多内容。
[1] 感谢Discord上的Wolf9466#9466
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post





















{kind=link}