Ergo a konsenzusný mechanizmus Autolykos: Časť II
20. júna 2022

Minulý týždeň sme predstavili hĺbkovú analýzu konsenzusného mechanizmu Autolykos v Ergu. S týmto článkom dokončujeme druhú časť tejto diskusie a ponoríme sa do ďalších podrobností. Pred čítaním tohto dokumentu sa odporúča, aby si čitatelia pozreli Časť I.
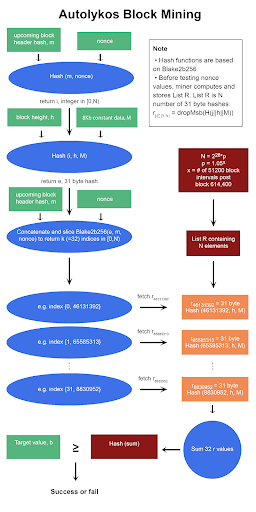
Na pripomenutie, tu sú pseudokódy pre ťažbu blokov a hashovaciu funkciu.
Pseudokód ťažby blokov Autolykos

Hashovacia funkcia založená na Blake2b256

Riadky 3, 4 – začiatok cyklu while a hádanie
Po vypočítaní listu R miner vytvorí nonce hádanie a vstúpi do cyklu, aby otestoval, či nonce nakoniec vytvorí výstup, ktorý je pod danou cieľovou hodnotou.
Riadky 5, 6 – semeno pre generovanie indexov
Riadok 5, i = takeRight(8, H(m||nonce)) mod N, produkuje celé číslo v [0,N). Algoritmus 3 sa využíva, ale s m a nonce ako vstupmi. Akonáhle je hash H(m||nonce) vrátený, 8 najmenej významných bajtov sa uchová a potom prejde cez mod N. Ako poznámku, najvyššia možná celočíselná hodnota s 8 bajtmi je 264 – 1, a predpokladajme, že N = 226, 8-bajtový hash mod N bude mať za následok, že prvé niekoľko číslic bude nula. Počet núl v i klesá, keď N rastie.
Riadok 6 produkuje e, semeno pre generovanie indexov. Algoritmus 3 sa volá s vstupmi i (vygenerovaným v riadku 5), h a M. Potom sa najvýznamnejší bajt numerického hashu zahodí a zostávajúcich 31 bajtov sa uchová ako hodnota e. Je tiež potrebné poznamenať, že hodnota e môže byť získaná z listu R namiesto toho, aby bola vypočítaná, pretože e je hodnota r.
Riadok 7 – generátor indexov
Element index J je vytvorený pomocou Algoritmu 6 s vstupmi e, m, a nonce. Funkcia genIndexes je pseudonáhodná jednosmerná funkcia, ktorá vracia zoznam k (=32) čísel v [0,N).
funkcia genIndexes

Existuje niekoľko ďalších krokov, ktoré nie sú zobrazené v pseudokóde, ako napríklad výmena bajtov. Vytvorenie a aplikácia genIndexes môžu byť vysvetlené prostredníctvom nasledujúceho príkladu:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash (t.j. výmena bajtov a spojenie 4 bajtov opakovaním prvých 4 bajtov) = [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBEB58CA, 0x4E641798, 0x86BFE8C0]
Nasledujúci python kód ukazuje proces krájania rozšíreného hashu, vracajúceho k indexy. V tomto príklade predpokladáme, že h < 614,400, takže N = 226 (67,108,864).
Krájanie a mod N[1]
for i in range(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32(ItemCount)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32(ItemCount)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32(ItemCount)
Hlavný záver je, že krájanie vracia k indexy, ktoré sú pseudonáhodné hodnoty odvodené zo semena, t.j. e, m, a nonce.
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
Tento index môže byť preložený na hodnoty v desiatkovej sústave, pretože sa odvoláva na čísla v [0, N). Napríklad, 0x2BFE8C0 = 46131392, 0x3E8C0A1 = 65585313, 0xC0A1BA = 12624314, a tak ďalej. Miner používa tieto indexy na získanie k r hodnôt.
Funkcia genIndexes zabraňuje optimalizáciám, pretože je mimoriadne ťažké, v podstate nemožné, nájsť semeno, tak aby genIndexes(seed) vrátil požadované indexy.
Riadok 8 – súčet r prvkov daných k
Použitím indexu generovaného v riadku 7, miner získa zodpovedajúce k (=32) r hodnoty z listu R a tieto hodnoty sčíta. To môže znieť mätúco, ale poďme to rozobrať.
Pokračujúc v príklade vyššie, miner uchováva nasledujúce indexy:
{0 | 46,131,392},
{1 | 65,585,313},
{2 | 12,624,314},
{3 | 10,599,011},
…
{31 | 8,830,952}
Na základe vyššie uvedených indexov miner získa nasledujúce r hodnoty z listu R uloženého v pamäti.
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12,624,314} → dropMsb(H(12,624,314||h||M))
{3 | 10,599,011} → dropMsb(H(10,599,011||h||M))
…
{31 | 8,830,952} → dropMsb(H(8,830,952||h||M))
Poznámka, že Takeright(31) operovaný na 32-bajtovom hashi môže byť tiež napísaný ako dropMsb – zahodiť najvýznamnejší bajt.
Keďže miner už uchováva list R v RAM, miner nemusí počítať k (= 32) Blake2b256 funkcií a namiesto toho vyhľadáva hodnoty. Toto je kľúčová vlastnosť odolnosti voči ASIC. ASIC s obmedzenou pamäťou musí vypočítať 32 iterácií Blake2b256, aby získal hodnoty, ktoré mohli byť vyhľadané v pamäti, a získavanie z pamäte trvá oveľa menej času. Nehovoriac o tom, že ASIC s obmedzenou pamäťou by vyžadoval 32 inštancií Blake2b256 fyzicky na die, aby dosiahol jeden hash na cyklus, čo by si vyžadovalo viac priestoru a vyššie náklady. Je jednoduché dokázať, že uchovávanie listu R v pamäti sa oplatí. Predpokladajme nasledujúce, GPU má hashovací výkon G = 100MH/s, _N = 226, k = 32, interval bloku t = 120 sekúnd, a prvky sa vyhľadávajú každé 4 hashe. Rád predpokladám, že prvky sa vyhľadávajú každé 4 hashe, pretože pre každé nonce hádanie vyžaduje viacero prvkov, ako sú i, J, a H(f), ktoré vyžadujú Algoritmus 3, t.j. inštancie blake2b hashu. Môžeme odhadnúť, že každá r hodnota bude použitá v priemere, (G * k * t)/(N*4) = 1430.51 krát.
Akonáhle sú 32 r hodnoty vyhľadané, sčíta sa.
Riadky 9, 10, 11, 12 – skontrolovať, či je hash súčtu pod cieľom
Súčet 32 r hodnôt sa hashuje pomocou Algoritmu 3, a ak je výstup pod cieľom b, PoW je úspešný, m a nonce sú vrátené uzlom siete a miner je odmenený v ERG. Ak je hash súčtu nad cieľom, Riadky 4 – 11 sa opakujú s novým nonce.
Ak ste sa dostali až sem, gratulujeme! Po prečítaní všetkých týchto informácií by ste mali mať dobré pochopenie Autolykos v2! Ak by ste chceli vidieť vizuálnu demonštráciu Autolykos, pozrite si grafiku na konci tohto dokumentu. Ak by ste chceli video vysvetlenie, môžete ho nájsť tu.
Odolnosť voči ASIC
Vieme z Etherea, že „pamäťovo náročné“ algoritmy môžu byť prekonané integráciou pamäte na ASIC. Ergo je iné, ale najprv si zopakujme, prečo je ASIC s obmedzenou pamäťou nekonkurenčný a prečo miner potrebuje uchovávať list R. Riadok 8 ťažby blokov Autolykos odrádza stroje s obmedzenou pamäťou. Ak miner ASIC neuchováva list R, vyžaduje veľa jadier na generovanie 31-bajtových numerických hashov na požiadanie. 32 r hodnoty nemôžu byť efektívne vypočítané pomocou jedného jadra, pretože výstup by bol generovaný iba každých 32. hash cyklu. Na to, aby sa vypočítalo jedno nonce na hash cyklus, je potrebných aspoň 32 inštancií Blake2b256 bežiacich dropMsb(H(j||h||M)). Ako sme už spomenuli, to výrazne zvyšuje veľkosť die a náklady. Je jasné, že uchovávanie listu R sa oplatí, pretože mať 32, alebo dokonca 16, jadier je veľmi drahé. Ešte presnejšie, čítanie z pamäte je rýchlejšie ako počítanie inštancií Blake zakaždým, keď je testované nonce.
Pozrime sa, či je ASIC s dostatočnou pamäťou konkurencieschopný, pretože to je relevantnejšie pre diskusiu. Porovnávaním Ethash a Autolykos je rozdiel v tom, že Ethash zahŕňa N prvkov pri hashovaní nonce a hlavička mixuje 64-krát, zatiaľ čo Autolykos zahŕňa N prvkov pri získavaní 32 r hodnôt na základe generovaných indexov. Pre každý testovaný nonce, Autolykos spúšťa asi 4 inštancie Blake2b256 a 32 vyhľadávaní pamäte, zatiaľ čo Ethash spúšťa asi 65 inštancií SHA-3 a 64 vyhľadávaní pamäte. Nehovoriac o tom, že k je momentálne nastavené na 32, ale táto hodnota môže byť zvýšená na získanie viac r hodnôt, ak je to potrebné. ASIC, ktoré bežia Ethash, majú veľa priestoru na zvýšenie rýchlosti hashovania SHA3, pretože 65 hashov sa dokončuje na každý testovaný nonce v porovnaní s približne 4 na Autolykos. Pomer vyhľadávaní pamäte k inštanciám hashovania je na Autolykos oveľa väčší. Z tohto dôvodu je Autolykos pamäťovo náročnejší ako Ethash, pretože šírka pásma pamäte zohráva oveľa väčšiu úlohu v porovnaní s rýchlosťou hashovania.
Oblasť, kde by sa mohla optimalizovať Autolykos, je naplnenie listu R. Naplnenie listu R vyžaduje N inštancií funkcie Blake2b256. N je veľké a len rastie, takže to je veľa hashovania. ASIC by mohol optimalizovať rýchlosť Blake2b256, čo by viedlo k viac času na ťažbu blokov, pretože list R by bol naplnený skôr. Aj keď sa to dá urobiť, naplnenie listu R si vyžaduje prechádzanie [0, N) a GPU s 32-širokými multiprocesormi už môže naplniť list R veľmi rýchlo (v sekundách). Na to, aby bol ASIC výrazne rýchlejší, by potreboval veľa Blake jadier – opäť, veľmi drahé a pravdepodobne to nestojí za to, pretože úzky bod by sa mohol stať šírkou pásma pamäte zapísať (t.j. zapisovanie listu R do RAM namiesto rýchlosti hashovania).
Posledná oblasť, ktorá môže byť optimalizovaná pre Autolykos, je rýchlosť čítania/zapisovania pamäte. ASIC mineri Ethash majú mierne rýchlejšiu rýchlosť čítania v porovnaní s GPU, pretože pamäť je taktovaná vyššie bez účinku obmedzenia GPU. Avšak tento rozdiel je dosť nevýznamný a očakáva sa, že sa stane ešte nevýznamnejším, keď sa GPU vyvinú. To je preto, že hardvér pamäte je sám o sebe rovnaký: DRAM. Môže sa objaviť otázka, či by sa mohol využiť rýchlejší hardvér pamäte, pri ktorom je rýchlosť čítania a zapisovania pamäte oveľa rýchlejšia… SRAM, napríklad, by mohol byť predstaviteľným ďalším krokom v prekonávaní pamäťovo náročných algoritmov, avšak SRAM nie je realizovateľným riešením jednoducho preto, že je menej husté.
SRAM na FPGA[2]

Na vyššie uvedenej fotografii je FPGA s 8 pamäťovými čipmi na prednej strane a ďalšími 8 na zadnej strane. Celková pamäť SRAM je iba 576MB. Umiestnenie dostatočného SRAM na die nebude fungovať, pretože SRAM bude musieť byť umiestnené ďalej od jadra, pretože nie je dostatočne husté na to, aby sa zmestilo do jednej vrstvy okolo jadra. To môže viesť k oneskoreniam pri čítaní/zapisovaní, pretože elektrina musí prechádzať dlhšie vzdialenosti, aj keď je hardvér sám rýchlejší. Okrem toho, na ťažbu Erga sa požiadavka na pamäť zvyšuje, keď N rastie, takže umiestnenie dostatočného SRAM nie je v priebehu času realizovateľné. Preto nie je vhodné skúmať SRAM ASIC, aj keď by mal niekto dostatok peňazí na samotný SRAM.
Blake2b256
Jedným z hlavných rozdielov medzi algoritmom ako Autolykos a inými je použitie Blake2b256. To nie je náhoda. Blake sa silne spolieha na operácie sčítania pre mixovanie hashov namiesto XOR operácií. Operácia ako XOR môže byť vykonaná bit po bite, zatiaľ čo sčítanie vyžaduje prenášacie bity. Preto Blake vyžaduje viac energie a plochy jadra v porovnaní s SHA algoritmami, ale je stále rovnako bezpečný a v skutočnosti rýchlejší. Ako je uvedené na webovej stránke Blake2, „BLAKE2 je rýchly v softvéri, pretože využíva vlastnosti moderných CPU, a to paralelizmus na úrovni inštrukcií, rozšírenia inštrukčného súboru SIMD a viacero jadier.“[3] Takže, aj keď ASIC môže produkovať inštancie Blake rýchlejšie, vnútorná povaha funkcie obmedzuje optimalizácie tým, že vyžaduje sčítanie a zahŕňa funkcie nájdené v CPU, ako aj GPU.
Rýchlosť Blake2b v porovnaní s inými hashovacími funkciami
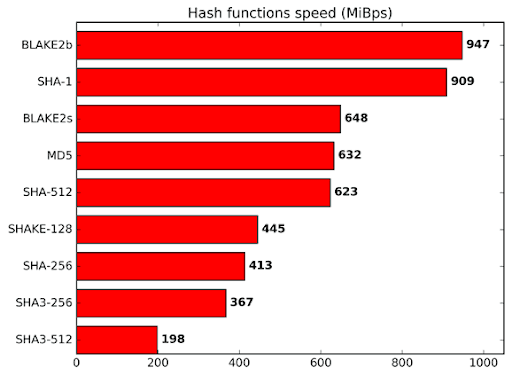
Záver
Autolykos je skvelá inovácia, ktorá je nevyhnutnou reakciou na boj proti vzostupu ASIC strojov optimalizovaných pre PoW. Dúfame, že táto dvojdielna séria vám pomohla pochopiť Autolykos na technickej úrovni a prečo je pamäťovo náročnejší ako Ethash. Keď Ethereum prechádza na sieť PoS, bude existovať veľká komunita minerov, ktorí hľadajú miesto, kam nasmerovať svoju hashovaciu silu, a Ergo by mal byť významným hráčom pri prilákaní týchto minerov.
Ak sa vám tento článok páčil, autor vás pozýva, aby ste si pozreli ďalší obsah prostredníctvom svojho Twitter účtu, @TheMiningApple.
[1] Kredit Wolf9466#9466 na Discorde
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post





9. júla 2025



{kind=link}