Ergo és az Autolykos Konszenzus Mechanizmus: II. rész
2022. június 20.

A múlt héten egy mélyreható felfedezést mutattunk be az Ergo Autolykos konszenzus mechanizmusáról. Ezzel a cikkel befejezzük a beszélgetés második részét, és további részletekbe merülünk. A dokumentum olvasása előtt ajánlott, hogy az olvasók nézzék meg az I. részt.
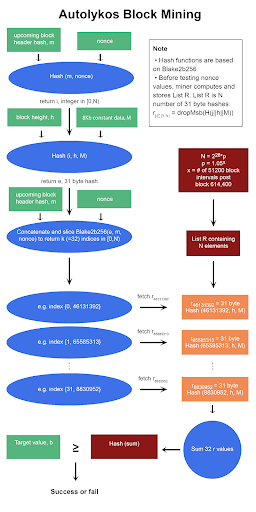
Emlékeztetőül, itt vannak a blokk bányászat és a hash függvény álkódjai.
Autolykos Blokk Bányászat Álkód

Blake2b256 Alapú Hash függvény

Sorok 3, 4 – kezdődik a while ciklus és a találgatás
A list R kiszámítása után a bányász létrehoz egy nonce találgatást, és belép egy ciklusba, hogy tesztelje, hogy a nonce végül egy olyan kimenetet hoz-e létre, amely a megadott célérték alatt van.
Sorok 5, 6 – mag a indexek generálásához
Az 5. sor, i = takeRight(8, H(m||nonce)) mod N, egy egész számot állít elő [0,N) tartományban. A 3. algoritmus használatos, de m és a nonce bemeneteként. Miután a hash H(m||nonce) visszatér, a 8 legkevésbé jelentős bájtot megtartják, majd átengedik mod N-en. Érdekességként megjegyzendő, hogy a legmagasabb lehetséges egész számérték 8 bájton 264 – 1, és feltételezve, hogy N = 226, egy 8 bájtos hash mod N esetén az első néhány számjegy nulla lesz. A i nulláinak száma csökken, ahogy N nő.
A 6. sor e-t, egy magot állít elő az index generálásához. A 3. algoritmus hívódik meg i (az 5. sorban generált), h, és M bemenetekkel. Ezután a numerikus hash legjelentősebb bájtját eltávolítják, és a fennmaradó 31 bájtot e értékként megtartják. Meg kell jegyezni, hogy az e érték a list R-ből is visszanyerhető, ahelyett, hogy kiszámítanák, mivel e egy r érték.
Sor 7 – index generátor
Az elem index J az 6. algoritmus segítségével jön létre e, m, és nonce bemenetekkel. A genIndexes függvény egy álképes, egyirányú függvény, amely egy k (=32) számot tartalmazó listát ad vissza [0,N) tartományban.
genIndexes függvény

Van néhány extra lépés, amely nem látható az álkódban, például egy bájtcsere. A genIndexes létrehozása és alkalmazása a következő példán keresztül magyarázható:
GenIndexes(e||m||nonce)...
hash = Blake2b256(e||m||nonce) = [0xF963BAA1C0E8BF86, 0x317C0AFBA91C1F23, 0x56EC115FD3E46D89, 0x9817644ECA58EBFB]
hash64to32 = [0xC0E8BF86, 0xF963BAA1, 0xA91C1F23, 0x317C0AFB, 0xD3E46D89 0x56EC115F, 0xCA58EBFB, 0x9817644E]
extendedhash (azaz, bájtcsere és 4 bájt összefűzése az első 4 bájt ismétlésével) = [0x86BFE8C0, 0xA1BA63F9, 0x231F1CA9, 0xFB0A7C31, 0x896DE4D3, 0x5F11EC56, 0xFBEB58CA, 0x4E641798, 0x86BFE8C0]
A következő python kód bemutatja az extended hash szeletelésének folyamatát, visszaadva a k indexeket. Ebben a példában feltételezzük, hogy h < 614,400, így N = 226 (67,108,864).
Szeletelés és mod N[1]
for i in range(8):
idxs[i << 2] = r[i] % np.uint32(ItemCount)
idxs[(i << 2) + 1] = ((r[i] << np.uint32(8)) | (r[i + 1] >> np.uint32(24))) % np.uint32(ItemCount)
idxs[(i << 2) + 2] = ((r[i] << np.uint32(16)) | (r[i + 1] >> np.uint32(16))) % np.uint32(ItemCount)
idxs[(i << 2) + 3] = ((r[i] << np.uint32(24)) | (r[i + 1] >> np.uint32(8))) % np.uint32(ItemCount)
A fő tanulság az, hogy a szeletelés k indexeket ad vissza, amelyek álképes értékek, amelyek a magból származnak, azaz e, m, és nonce.
return [0x2BFE8C0, 0x3E8C0A1, 0xC0A1BA, 0xA1BA63, 0x1BA63F9, 0x263F923, 0x3F9231F, 0x1231F1C, 0x31F1CA9, 0x31CA9FB, 0xA9FB0A, 0x1FB0A7C, 0x30A7C31, 0x27C3189, 0x31896D, 0x1896DE4, 0x16DE4D3, 0x1E4D35F, 0xD35F11, 0x35F11EC, 0x311EC56, 0x1EC56FB, 0x56FBEB, 0x2FBEB58, 0x3EB58CA, 0x358CA4E, 0xCA4E64, 0x24E6417, 0x2641798, 0x179886, 0x39886BF, 0x86BFE8]
Ez az index átváltható 10-es alapú értékekre, mivel a [0, N) tartományban lévő számokra utal. Például, 0x2BFE8C0 = 46131392, 0x3E8C0A1 = 65585313, 0xC0A1BA = 12624314, és így tovább. A bányász ezeket az indexeket használja k r értékek visszakeresésére.
A genIndexes függvény megakadályozza az optimalizálásokat, mivel rendkívül nehéz, gyakorlatilag lehetetlen olyan magot találni, amelynek genIndexes(mag) a kívánt indexeket adja vissza.
Sor 8 – r elemek összege adott k
A 7. sorban generált index segítségével a bányász visszakeresi a megfelelő k (=32) r értékeket a list R-ből, és ezeket az értékeket összeadja. Ez zavarónak tűnhet, de bontsuk le.
Folytatva a fenti példát, a bányász a következő indexeket tárolja:
{0 | 46,131,392},
{1 | 65,585,313},
{2 | 12,624,314},
{3 | 10,599,011},
…
{31 | 8,830,952}
A fenti indexek alapján a bányász a következő r értékeket keresi a memóriában tárolt list R-ből.
{0 | 46,131,392} → dropMsb(H(46,131,392||h||M))
{1 | 65,585,313} → dropMsb(H(65,585,313||h||M))
{2 | 12,624,314} → dropMsb(H(12,624,314||h||M))
{3 | 10,599,011} → dropMsb(H(10,599,011||h||M))
…
{31 | 8,830,952} → dropMsb(H(8,830,952||h||M))
Megjegyzendő, hogy a Takeright(31) egy 32 bájtos hash-en is írható dropMsb-ként – eltávolítva a legjelentősebb bájt.
Mivel a bányász már tárolja a list R-t a RAM-ban, a bányásznak nem kell k (= 32) Blake2b256 függvényt kiszámítania, hanem a értékeket egyszerűen megkeresi. Ez az ASIC ellenállás kulcsfontosságú jellemzője. Egy korlátozott memóriájú ASIC-nak 32 Blake2b256 iterációt kell kiszámítania, hogy megkapja azokat az értékeket, amelyeket a memóriából meg lehetett volna keresni, és a memóriából való lekérés sokkal kevesebb időt vesz igénybe. Nem is beszélve arról, hogy egy korlátozott memóriájú ASIC-nak 32 Blake2b256 példányra lenne szüksége fizikailag a chipen, hogy egy hash-t érjen el ciklusonként, ami nagyobb területet és magasabb költségeket igényelne. Egyszerűen bizonyítható, hogy a list R memóriában való tárolása megéri a cserét. Tegyük fel, hogy egy GPU hash sebessége G = 100MH/s, _N = 226, k = 32, blokk intervallum t = 120 másodperc, és az elemeket minden 4 hash-nél keresik. Szeretem feltételezni, hogy az elemeket minden 4 hash-nél keresik, mert minden nonce találgatás esetén több elem, mint például i, J, és H(f) igényli a 3. algoritmust, azaz blake2b hash példányokat. Becslésünk szerint minden r értéket átlagosan (G * k * t)/(N*4) = 1430.51 alkalommal használnak.
Miután a 32 r értéket megkeresték, összeadják őket.
Sor 9, 10, 11, 12 – ellenőrizze, hogy a összeg hash-e a cél alatt van-e
A 32 r érték összege a 3. algoritmus segítségével hash-elve van, és ha a kimenet a cél b alatt van, a PoW sikeres, m és nonce visszatér a hálózati csomópontokhoz, és a bányászt ERG-ben jutalmazzák. Ha az összeg hash a cél felett van, a 4 – 11. sorok megismétlődnek egy új nonce-szal.
Ha eddig eljutottál, gratulálok! Miután elolvastad ezt az információt, jó megértésed kell, hogy legyen az Autolykos v2-ről! Ha vizuális bemutatót szeretnél látni az Autolykosról, kérlek nézd meg a dokumentum végén található grafikont. Ha videós magyarázatot szeretnél, azt itt találod.
ASIC Ellenállás
Tudjuk az Ethereumból, hogy a „memória nehéz” algoritmusokat meg lehet hódítani az ASIC-ek memóriájának integrálásával. Az Ergo más, de először nézzük át, miért nem versenyképes egy korlátozott memóriájú ASIC, és miért szükséges a bányásznak tárolnia a list R-t. Az Autolykos blokk bányászat 8. sora elriasztja a korlátozott memóriájú gépeket. Ha egy ASIC bányász nem tárolja a list R-t, sok magra van szüksége a 31 bájtos numerikus hash-ek azonnali generálásához. 32 r értéket nem lehet hatékonyan kiszámítani egyetlen magos ciklus használatával, mert egy kimenet csak minden 32. hash ciklusban jön létre. Tekintettel J-re, egy nonce kiszámításához hash ciklusonként legalább 32 Blake2b256 példány futtatása szükséges dropMsb(H(j||h||M)). Ahogy fent említettük, ez jelentősen növeli a chip méretét és költségét. Nyilvánvaló, hogy a list R tárolása megéri, mert 32, vagy akár 16 mag nagyon drága. Pontosabban, a memória olvasása gyorsabb, mint a Blake példányok kiszámítása minden alkalommal, amikor egy nonce-t tesztelnek.
Nézzük meg, hogy egy elegendő memóriával rendelkező ASIC versenyképes-e, mert ez relevánsabb a beszélgetéshez. Az Ethash és az Autolykos összehasonlításakor a különbség az, hogy az Ethash N elemet von be a nonce hash-elésekor, és a fejlécet 64-szer keveri, míg az Autolykos N elemet von be, amikor 32 r értéket keres az előállított indexek alapján. Minden tesztelt nonce esetén az Autolykos körülbelül 4 Blake2b256 példányt futtat és 32 memória lekérést végez, míg az Ethash körülbelül 65 SHA-3-szerű példányt futtat és 64 memória lekérést végez. Nem is beszélve arról, hogy k jelenleg 32-re van állítva, de ez az érték növelhető, ha szükséges több r érték visszanyeréséhez. Az Ethash-t futtató ASIC-oknak sok lehetőségük van a SHA3 hash sebességének növelésére, mivel 65 hash-t végeznek el minden tesztelt nonce esetén, míg az Autolykos esetében körülbelül 4 hash-t. A memória lekérések és a hash példányok aránya sokkal nagyobb az Autolykos esetében. Ezért az Autolykos memória nehezebb, mint az Ethash, mivel a memória sávszélesség sokkal nagyobb szerepet játszik a hash sebességéhez képest.
Az Autolykos optimalizálásának egy területe a list R feltöltése lehet. A list R feltöltése N példányt igényel a Blake2b256 függvényből. N nagy és csak növekszik, így ez sok hash-elést jelent. Egy ASIC optimalizálhatja a Blake2b256 sebességét, így több időt nyerhet a blokk bányászatához, mivel a list R hamarabb telítődik. Bár ezt meg lehet tenni, a list R feltöltése megköveteli a [0, N) áthaladását, és egy 32 széles multiprocesszorral rendelkező GPU már nagyon gyorsan (másodpercek alatt) képes feltölteni a list R-t. Szükség lenne egy ASIC-ra, amely sok Blake maggal rendelkezik, hogy jelentősen gyorsabb legyen – ismét, nagyon drága, és valószínűleg nem éri meg, mivel a szűk keresztmetszet a memória írás sávszélesség lehet (azaz a list R RAM-ba írása, nem pedig a hash sebessége).
Az utolsó terület, amely optimalizálható az Autolykos számára, a memória olvasási/írási sebesség. Az Ethash ASIC bányászoknak kissé gyorsabb az olvasási sebességük a GPU-kkal szemben, mivel a memória magasabb órajelen működik, anélkül, hogy a GPU korlátozása hatással lenne. Azonban ez a különbség elég jelentéktelen, és várhatóan még jelentéktelenebbé válik, ahogy a GPU-k fejlődnek. Ennek az az oka, hogy a memória hardver maga ugyanaz: DRAM. Felmerülhet a kérdés, hogy lehet-e gyorsabb memória hardvert használni, amelynél a memória olvasási és írási sebesség sokkal gyorsabb... Az SRAM például elképzelhető következő lépés lehet a memória nehéz algoritmusok megtörésében, azonban az SRAM nem megvalósítható megoldás, mivel kevésbé sűrű.
SRAM FPGA-n[2]

A fenti fénykép egy FPGA, amelyen 8 memóriachip található elöl, és még 8 a hátulján. A teljes SRAM memória csak 576MB. Elegendő SRAM elhelyezése egy chipen nem működik, mert az SRAM-nak távolabb kell elhelyezkednie a magtól, mivel nem elég sűrű ahhoz, hogy egy rétegben körülvegye a magot. Ez olvasási/írási késleltetéseket okozhat, mivel az áramnak hosszabb távolságokat kell megtennie, még akkor is, ha a hardver maga gyorsabb. Ezenkívül az Ergo bányászatához a memóriaigény növekszik, ahogy N növekszik, így elegendő SRAM elhelyezése nem megvalósítható az idő múlásával. Így az SRAM ASIC-ok nem érdemesek a felfedezésre, még akkor sem, ha valakinek elég pénze lenne az SRAM-ra.
Blake2b256
Az Autolykos és más algoritmusok közötti egyik fő különbség a Blake2b256 használata. Ez nem véletlen. A Blake nagymértékben támaszkodik az összeadási műveletekre a hash keverés során, nem pedig az XOR műveletekre. Az XOR művelet bitről bitre végezhető, míg az összeadás hordozó biteket igényel. Így a Blake több energiát és magterületet igényel a SHA algoritmusokhoz képest, de még mindig olyan biztonságos, és valójában gyorsabb. Ahogy a Blake2 weboldalán említik, "A BLAKE2 gyors a szoftverben, mert kihasználja a modern CPU-k jellemzőit, nevezetesen az utasítás szintű párhuzamosságot, a SIMD utasításkészlet kiterjesztéseit és a több magot.”[3] Így, míg egy ASIC gyorsabban tudja kiadni a Blake példányokat, a funkció belső természete korlátozza az optimalizálásokat, mivel összeadást igényel, és olyan jellemzőket von be, amelyek a CPU-kban és a GPU-kban találhatók.
Blake2b sebessége más hash függvényekhez viszonyítva
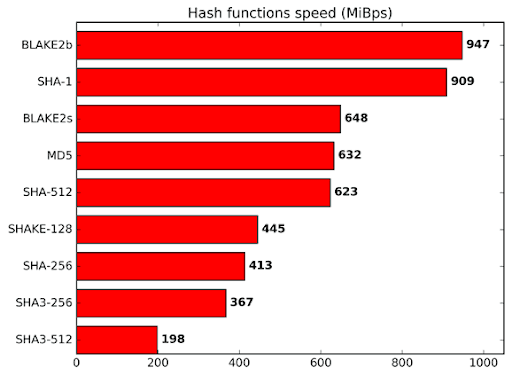
Következtetés
Az Autolykos egy nagyszerű innováció, amely szükséges válasz a PoW-optimalizált ASIC gépek megjelenésére. Reméljük, hogy ez a 2 részes sorozat segített megérteni az Autolykost egy technikai szinten, és miért nehezebb memória szempontjából, mint az Ethash. Ahogy az Ethereum átáll a PoS hálózatra, egy nagy közösség bányásza keres majd helyet a hashrate erejének irányítására, és az Ergo jelentős szereplővé válhat a bányászok vonzásában.
Ha tetszett ez a cikk, a szerző meghívja Önt, hogy nézzen meg több tartalmat a Twitter fiókján, @TheMiningApple.
[1] Köszönet Wolf9466#9466-nak a Discordon
[2] http://www.ldatech.com/_images/imageGallery/SBM09P-3_front.jpg
[3] https://www.blake2.net/#:~:text=A%3A%20BLAKE2%20is%20fast%20in,of%20the%20designers%20of%20BLAKE2).
Share post

2025. augusztus 13.

2025. augusztus 12.



2025. július 9.

2025. május 12.

{kind=link}